
Forecasting
Forecasting is een belangrijke component van theoretisch en praktisch voorraadbeheer. Het geeft het antwoord op het ‘hoeveel en wanneer bestellen’: de twee fundamentele vraagstukken binnen voorraadbeheer.
- AGENDA
- WIKI
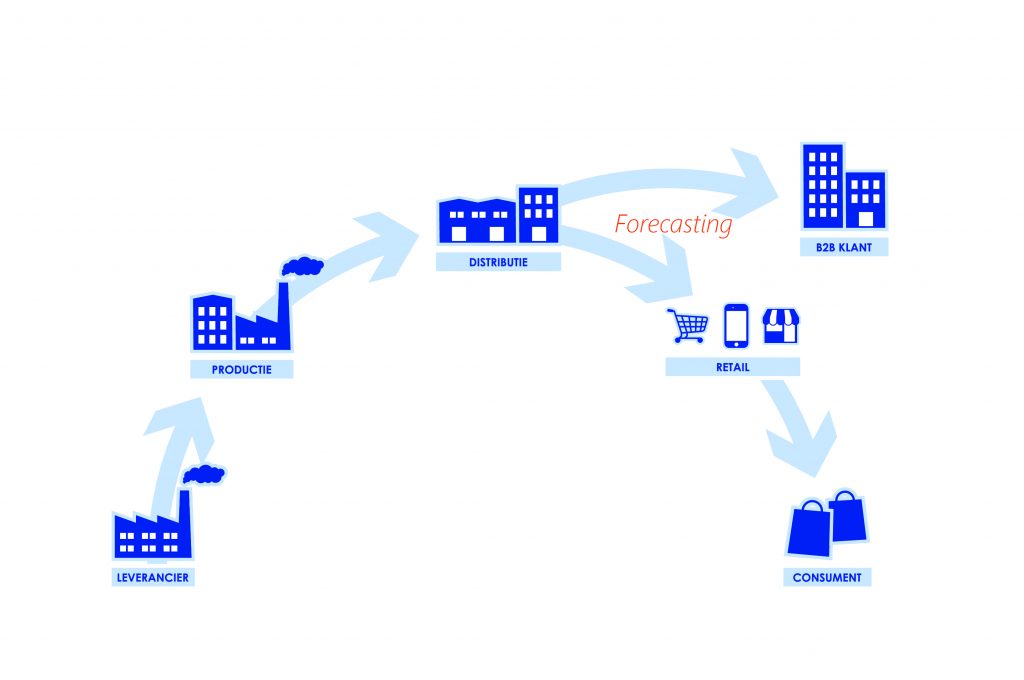
Wat is forecasting?
Forecasting is het zo goed mogelijk reproduceren van historische vraagpatronen. Dit helpt ons om de vraag gedurende een bepaalde tijd beter te begrijpen, wat ons in staat stelt een scenario uit te denken voor de toekomst inzake de klantvraag. Binnen een bedrijf ontstaat voorraad en de hoeveelheid ervan wordt bepaald door 3 belangrijke factoren:
– Tijdverschillen: Er gaat een bepaalde tijd over het moment van bestelling tot het moment dat de goederen beschikbaar zijn voor verkoop. Het is vanzelfsprekend dat als deze tijd langer is dan de tijd dat een klant op zijn product wil wachten, dat we voorraad in onze magazijnen moeten houden. Forecasting speelt hier de grootste rol omdat we moet bepalen welke vraag er statistisch gezien met de grootste kans voorkomt: namelijk het gemiddelde van de klantvraag.
– Onzekerheid: In een dynamische omgeving loopt echter niet alles volgens het gemiddelde; het loopt dus niet zoals men het altijd wenst. Enerzijds is de klantvraag onzeker en anderzijds is onze productiedoorlooptijd en/of onze levertijd niet altijd met zekerheid te herleiden tot een fixed getal. Om deze onzekerheid op te vangen en zo ook andere scenarios op te kunnen vangen, zullen we extra voorraad moeten neerleggen.
– Economische motieven: Voorraden zullen ontstaan als gevolg van een reeks kostenafwegingen ( zogenaamde trade-off modellen). Het ‘hoeveel’ bestellen is een afweging tussen bestel- en voorraadkosten (EOQ: zie afbakening) en het ‘ wanneer bestellen’ zal een afweging zijn tussen voorraadkosten de marge op een product a.k.a. de service kost (service levels: zie afbakening).
Het bereikte evenwicht hangt in grote mate af waarin we bepaalde logistieke taken efficiënt kunnen vervullen. Zo kunnen we of bijvoorbeeld de omsteltijd reduceren of een opslagplaats reduceren. Maar ook de juiste assortimentsbeslissingen maken, beter forecasten en kwalitatief data beheer kan allemaal bijdragen tot een beter evenwicht en dusdoende een lagere voorraadhoogte. De voorraadhoogte is dus (of hoort zo te zijn) het resultaat van een ‘trade-off’ analyse.
Afbakening Forecasting
Data: Omdat vraagpatronen zich kunnen manifesteren over verschillende jaren, is het vanzeflsprekend dat voldoende data een eerste verreiste is binnen forecasting. Niet alleen de hoeveelheid data, maar ook de juiste data is belangrijk. De vraagpatronen worden meer en meer sterk beïnvloed door klantspecifieke transacties, wat ervoor zorgt dat het gebruik van geaggregeerde data een dodelijke vertraging teweeg brengt in het forecasten.
Kennis: Een tweede verreiste is de theoretische kennis omtrent forecasting. Omdat we vraagpatronen moeten herkennen is het belangrijk dat we kennis hebben van zowel de mogelijke vraagpatronen, de voorspelmethodieken per vraagpatroon én het herkennen van structurele veranderingen in het vraagpatroon.
Software: Dit brengt ons direct bij een derde verreiste binnen forecasting: software.
Het toepassen van voorspelmethodieken, correlaties( het toetsen van vraagpatronen) en het snel sturen op veranderingen in het vraagpatroon vragen enorm veel tijd en rekenkracht. Zaken waarbij een software een cruciale rol kunnen spelen.
Communicatie: De communicatie tussen leverancier en klant bepaalt in zeer grote mate hoe goed er geforecast kan worden. Het alombekende bullwhip effect veroorzaakt afwijkingen in de forecast die vermeden kunnen en móeten worden om optimaal te kunnen voorspellen.
Proces: Hoe we het inkoop- en verkoopproces inrichten kan mee bepalen hoezeer de forecast ‘zuiver’ wordt gehouden. Productieproblemen, promoties, inkoopkortingen, etcetera zijn allemaal dingen die de vraagpatronen artificieel kunnen beïnvloeden. Zuivere vraagpatronen vragen om een zuiver proces. De vraag van de praktijk blijft dan wat dit opbrengt en of dit opweegt tegen het vermijden van al die zogezegde marge genererende processen.
Vraagdecompositie: Veelal wordt er minder goed geforecast omdat de werkelijke klantbehoefte niet doorkomt. Enerzijds hebben we hier de juiste data voor nodig en anderzijds moet er de juiste communicatie tussen klant en leverancier zijn. Echter, deze twee zaken dienen nog een analytische brug te hebben om vanuit de data naar de juiste communicatie te gaan. Dit kan door de techniek ‘vraagdecompositie’. Vandaar dat deze term een aparte afbakening dient te hebben binnen het verhaal rond forecasting.
Key Performance Indicators (KPI’s)
Als we praten over KPI’s omtrent forecasting, dan moeten we ons de vraag stellen: welke indicatoren geven nu precies aan hoe goed ik voorspel?
In feite moet men checken hoe goed de gebruikte voorspelmethodiek de historische vraag kan reproduceren, met enkel de data van historische data daarvoor. Hiervoor maakt men best gebruik van een ‘initiatie’ data set en een test set.
Hiernaast willen we natuurlijk weten of de fout die de methodiek maakt invloed heeft op mijn service en bijgevolg op de demand planning.
Men kan ook bepaalde productgroepen willen vergelijken inzake voorspellen.
De methodieken zijn rijkelijk; dewelke je dient te gebruiken hangt af van welk doel je voor ogen hebt. We lichten er de belangrijkste uit:
- Tracking Signal: Dit cijfer geeft aan of we structureel teveel of teweinig voorspellen. Dit signaal is enorm belangrijk, omdat dit ons kan sturen in het gebruik van voorspellingsmethodieken. Het berekent simpelweg of je voorspelfout groter wordt. Zodra dit cijfer verder van 0 beweegt, negatief of positief, zal dit duiden op het feit dat de voorspelling structureel te hoog of te laag is.
- Mean error (ME): Elke voorspelmethodiek bepaalt een gemiddelde. Een voorspelling is goed wanneer er een beperkte fout plaatsvindt die structureel boven en onder dat gemiddelde beweegt. Hoe kleiner deze fout, hoe beter de voorspelmethodiek past bij dat vraagpatroon.
Deze fout kan mathematisch alsvolgt genoteerd worden:
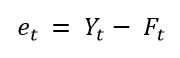
,waarbij et de fout voorstelt, Yt de werkelijke vraag van periode t en Ft de voorspelling als output van de voorspelmethodiek voor diezelfde periode t.
De mean error is simpelweg de gemiddelde fout die we maken over n-periodes. Deze bereken je dus door volgende formule toe te passen:
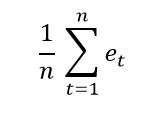
- Mean Absolute Error (MAE): Waar de vorige fout simpel was om te berekenen, zien we toch een probleem opduiken. We zeiden dat elke fout mooi rond het gemiddelde bewoog. Op die manier kan het goed zijn dat de mean error 0 is. De output van de techniek is dus ongeveer dezelfde als die van het tracking signal, maar dan simpeler om te berekenen. We noemen daarom de mean error ook wel de forecasting bias.
Om toch een indicatie te krijgen van de fout die een voorspelling maakt, kunnen we dezelfde formule toepassen, maar door eerst de fout et absoluut te maken. Hier maken we simpelweg elk negatief getal positief. De formules voor et en de mean absolute error worden dan
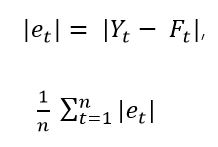
,
Deze fout kan ons ook een indicatie geven of onze service in de problemen komt (nvda.: het artikel ‘het geheim achter beter voorspellen’ geeft hier meer duidelijkheid in).
- Mean absolute percentage error (MAPE): Voorgaande metingen spraken tot dusver altijd in stuks. Het is daarom gevaarlijk om dit soort metingen te gebruiken om over grotere assortimentsgroepen te gaan kijken naar de juistheid van voorspelmethodieken, zeker als de voorspelperiode niet gelijk is en/of de artikeleigenschappen inzake verbruik/verkoop niet vergelijkbaar zijn met elkaar.
Als je het doel hebt de voorspelfout te beoordelen over verschillende artikelgroepen heen, kan je best de ‘mean absolute percentage error’ gebruiken. Dit is in feite de percentuele vorm van de mean absolute error.
We beginnen allereerst om de error et om te zetten naar een percentage. We krijgen dan de percentage error ( PEt)
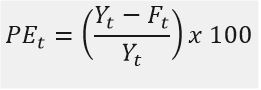
Dit brengt ons naar de formule van de mean absolute percentage error, die de mean absolute error combineert met de percentage error van hierboven
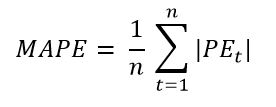
Interessante bronnen
Makridakis, S.C. Wheelright, R.J. Hyndman [1998]
Forecasting, Methods and Applications
Axsäter S. [2006]
Inventory Control
Springer
Marc Lambrecht [2005]
Handboek productie- en voorraadbeheer
Wolters Plantyn
John A. Muckstadt, Amar Sapra [2010]
Principles of inventory management
when you are down to four, order more
Springer
Tony Wild [2002]
Best practice in inventory management
Routledge
Wallace J. Hopp, Mark L Spearman [2008]
Factory Physics, Third Edition
McGraw-Hill Education-Europe
Durlinger P, Pauly S [2016]
Vraagdecompositie
Durlinger Consultancy
Pauly S [2016]
Het geheim achter beter voorspellen
Slimstock B.V.
Deze service is gericht op IMCC-leden. Wij vragen u in te inloggen voordat u een vraag gaat stellen.
Deze service is gericht op IMCC-leden. Wij vragen u in te inloggen voordat u een vraag gaat stellen.
- LEDEN







![]()
Op gebruik van deze website is ons Privacy Statement van toepassing.